
Does "Thinking" Always Help an LLM?
High reasoning wins more often, especially on structured, instruction-heavy tasks, but it can stumble on exact code/SQL/schema work.


TL;DR
I ran ~100 hard, instruction-heavy tasks on the same base model (gpt-5.1) with three reasoning settings: none, low, and high. The high-reasoning variant had the highest average score and was picked best about half the time.
The biggest gains are on structured, multi-step, format-constrained tasks (analysis plans, comms, structured writing, accessible frontend). On precise code, SQL, and schema tasks, extra reasoning sometimes adds small syntax or logic errors.
Use high reasoning for complex, instruction-heavy prompts, and always pair it with tests or validation when the output must be executable (code, SQL, schemas).
All data, prompts, code are shared at the end of article
Why I Ran This
I wanted to understand a simple question:
If I only change the reasoning setting on a model, does quality actually improve, and where?
Using the same base model (gpt-5.1), I varied only reasoning.effort:
model_1: reasoning nonemodel_2: reasoning lowmodel_3: reasoning high
I then checked:
Does higher reasoning effort improve instruction following and correctness?
Is the benefit uniform across task types, or concentrated in a few?
This was partly inspired by the Apple paper “The Illusion of Thinking” and by watching ChatGPT “think” at length on prompts where it did not seem to help.
Task Setup in Brief
I asked gpt-5.1 with high reasoning to generate all tasks, with instructions to make them:
Instruction heavy, multi step, and non trivial
Focused on realistic domains like SQL and analytics, Python jobs, frontend components, communications, docs and schemas, and planning or writing
Strict about format, for example “return only code blocks, JSON, or ordered sections”
Full of edge cases and explicit constraints, and to avoid simple or one line tasks
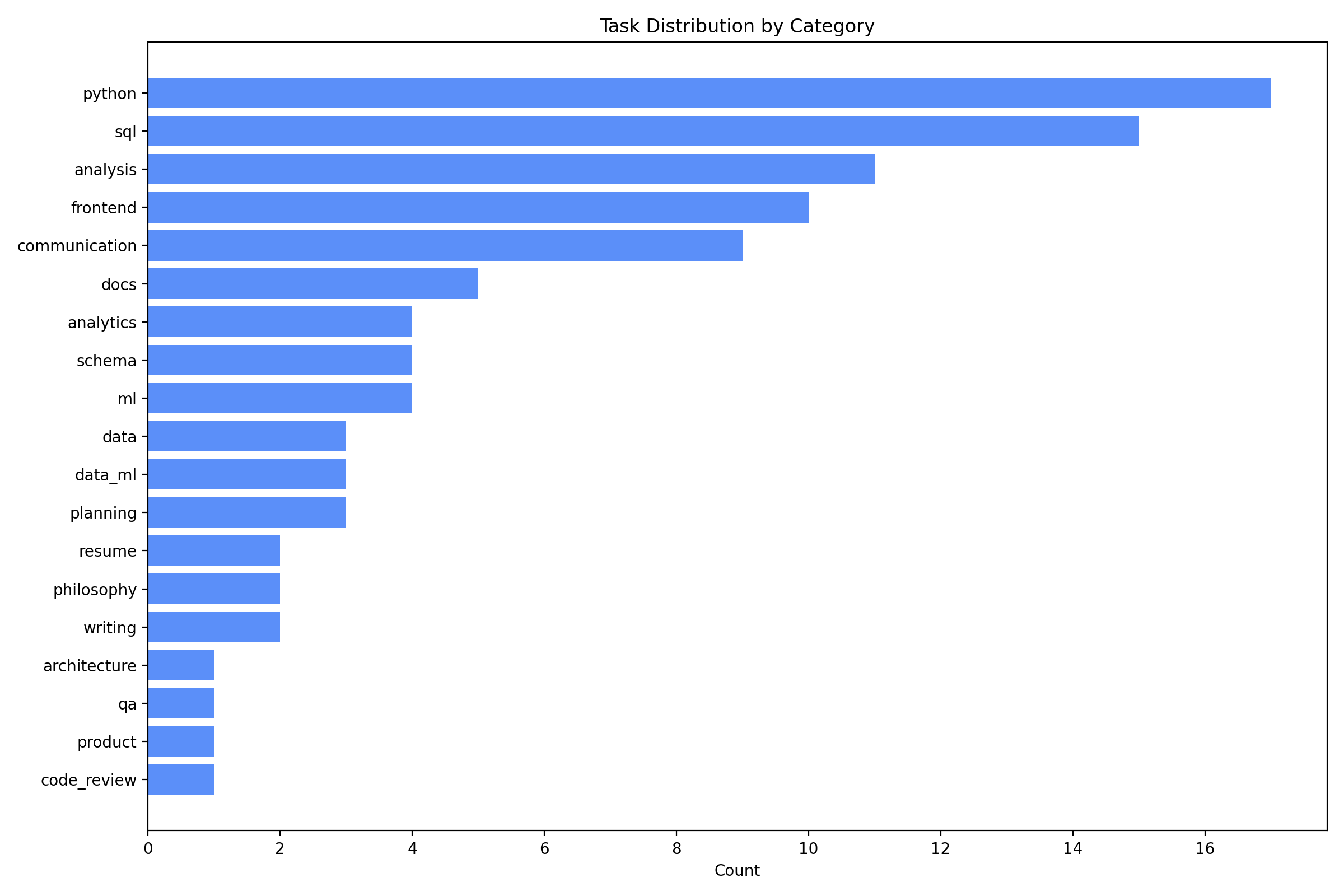
I deduped by (category, task_name, prompt) and ended up with 98 tasks.
How I Evaluated
For each task:
Answer generation
I called gpt-5.1 three times with the same prompt, once with each reasoning setting, and stored the outputs asmodel_1,model_2, andmodel_3.Scoring
Another gpt-5.1 instance(could setup another LLM model here), acting as a strict grader, scored each answer from 0 to 10.
Scores were penalized for:Wrong format (for example, extra text when the prompt asked for “JSON only”)
Broken ordering or missing required sections
Clear logical or syntax errors
Best pick
The grader then saw all three answers and had to pick one best model, no ties. This gives a “win rate” per model in addition to average scores.
I also broke down results by broad category (sql, python, frontend, analysis, communication, schema, docs, planning, writing, and so on).
Results
Across all 98 tasks:
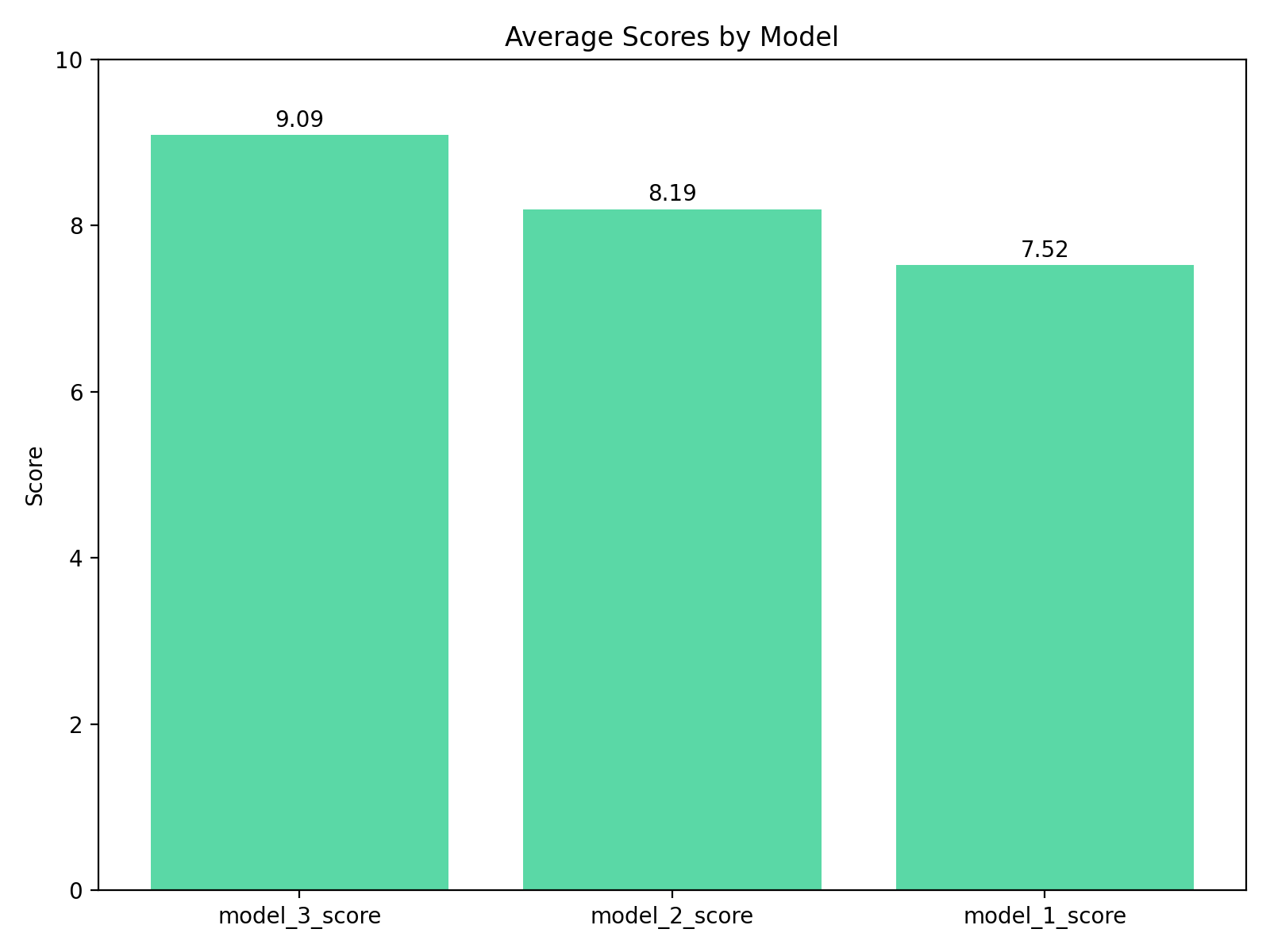
Average scores
model_1 (none): 7.52
model_2 (low): 8.19
model_3 (high): 9.09
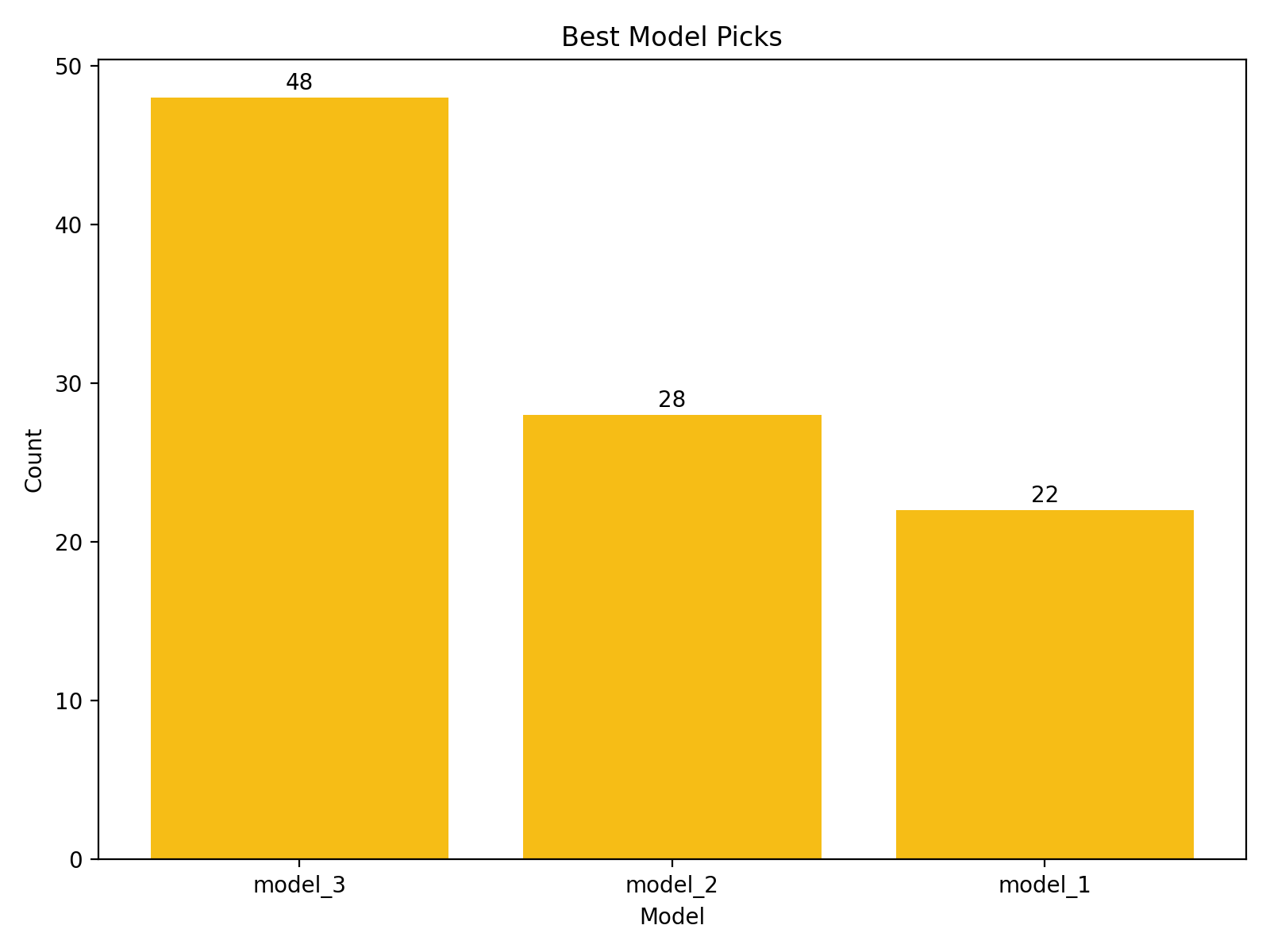
Best model picks
model_1: 22.4% of tasks
model_2: 28.6% of tasks
model_3: 49.0% of tasks
model_3 wins most often, but the other two still win a meaningful fraction of tasks.
Where High Reasoning Helps Most
Looking by category, in this experiment, high reasoning shines where tasks are multi-step and format constrained:
Analysis plans and analytics writeups
Communications with strict sections (for example, incident updates or executive summaries)
Structured planning and writing tasks
Accessible frontend components that combine behavior, structure, and constraints
In these cases, model_3 often:
Uses all required sections and ordering
Respects “only output X format” instructions
Covers more edge cases or reasoning steps that the other variants miss
The category score lift plot makes this visible:
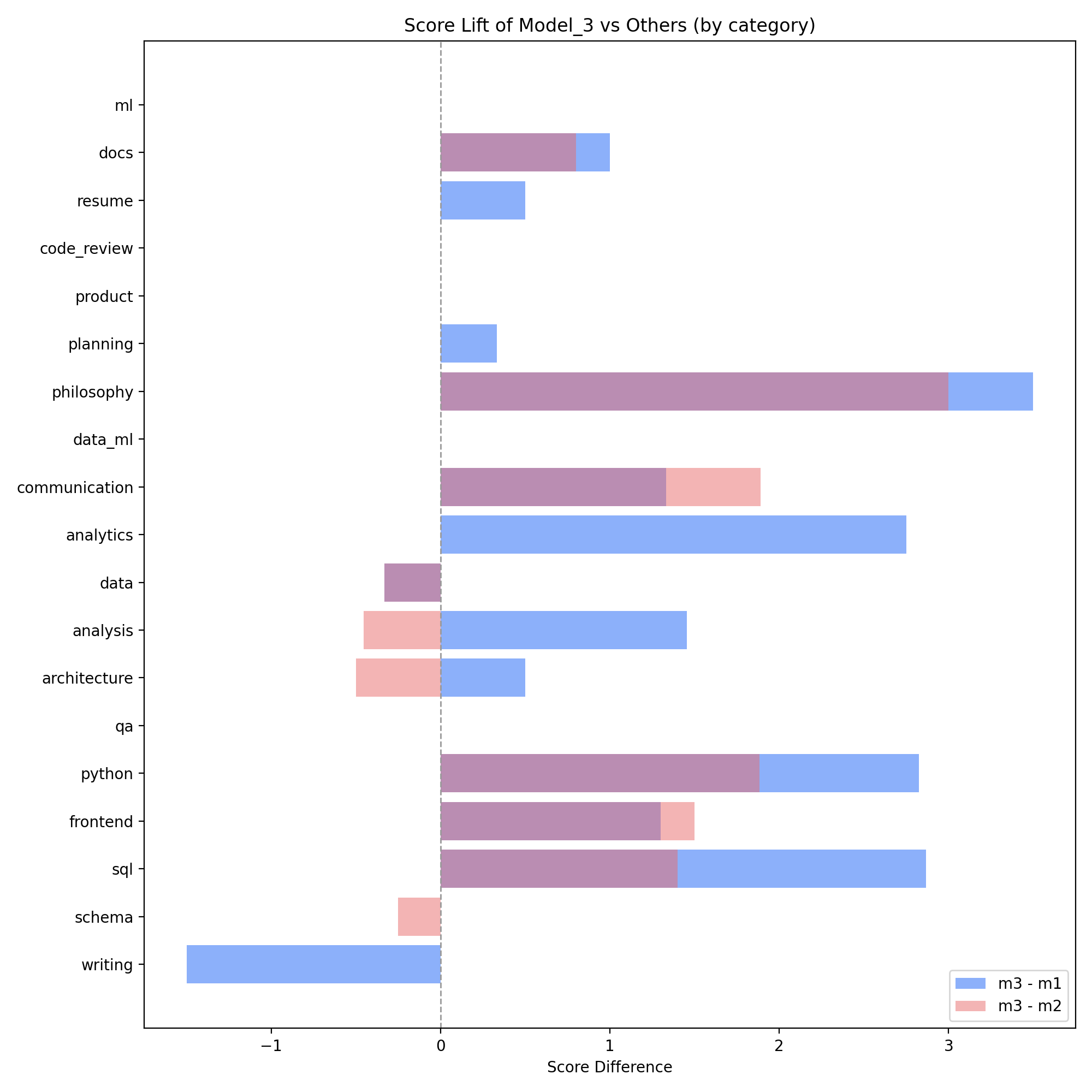
Bars to the right are categories where high reasoning clearly adds value. For example, analysis, communication, planning, resume, and philosophy all see a strong lift.
Where High Reasoning Falls Short
High reasoning did not win everywhere.
On several categories that demand exactness:
SQL queries
JSON schemas
Some Python snippets
There are cases where model_3 produced a rich, well explained answer with one small syntax or logic error, while model_2 or model_1 produced something simpler but correct enough to win under the rubric.
Some patterns:
In SQL related tasks, model_2 actually won slightly more tasks than model_3, even though model_3 had the best average score.
In schema related task, wins were roughly split between model_2 and model_3.
In a couple of writing tasks that demanded a very strict format, model_1 won because it simply followed the format while the higher reasoning variants tried to be more creative.
The lesson is simple:
Extra “thinking” can still introduce small mistakes on deterministic tasks where a missing comma or a wrong join breaks the whole thing.
Limitations of this exercise: I used the same model family (gpt-5.1) to grade, took only one sample per model per task, and had 98 tasks with some thin categories, so results are directional and do not account for cost or latency.
Results and code are posted here: Reasoning Test